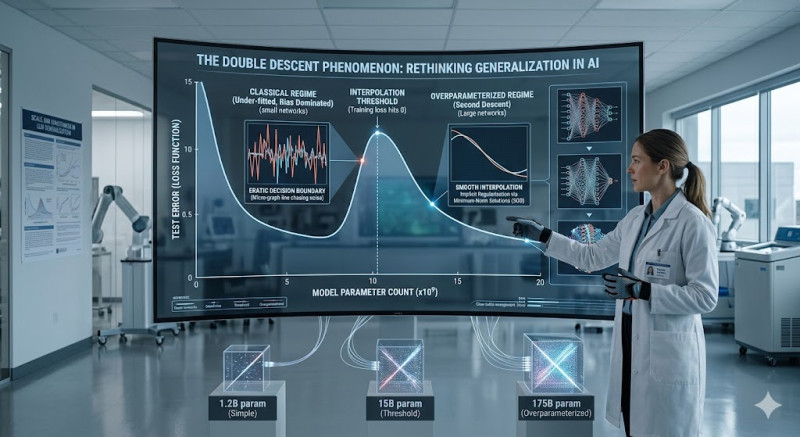
For decades, one of the foundational pillars of statistical learning theory was the classical Bias-Variance Trade-off. According to this traditional paradigm, as a model’s complexity increases, its training error decreases, but its test error follows a U-shaped curve. Beyond a certain optimal threshold of complexity, adding more parameters leads to overfitting—where the model begins to memorize the noise in the training data rather than learning the underlying distribution, causing the generalization error to skyrocket.
The Classical Paradigm vs. Deep Learning Reality
However, modern deep learning practice has consistently defied this classical wisdom. State-of-the-art models, such as Large Language Models (LLMs) and massive vision transformers, possess an astronomical number of parameters—often vastly exceeding the number of training data points ($N$). According to textbook theory, these extremely overparameterized networks should suffer from catastrophic overfitting. Yet, they generalize remarkably well to unseen data. This paradox led researchers to discover a broader framework known as Deep Double Descent.
Anatomy of the Second Descent
The double descent phenomenon demonstrates that the test error curve behaves in a much more fascinating way than previously thought. As model capacity or training time increases, the performance graph transitions through three distinct phases:
-
The Under-fitting and Classical Regime: Initially, as the number of parameters increases, the model learns meaningful features, and test error drops. Eventually, it reaches the classical capacity limit, where it starts overlearning noise, causing the test error to climb upward.
-
The Interpolation Threshold: This is the critical peak where the test error reaches its maximum. At this precise boundary, the model has just enough capacity to achieve perfect fit—meaning the training error reaches zero ($R_{train} \approx 0$). Because the model is forced to fit every data point perfectly with minimal redundant capacity, the resulting decision boundaries become highly erratic and sensitive to noise, leading to worst-case generalization.
-
The Overparameterized Regime (The Second Descent): Once the number of parameters grows far beyond the interpolation threshold, the test error begins to decline once again. In this ultra-high-dimensional space, the model becomes heavily under-determined, meaning there are infinitely many interpolating functions that can perfectly fit the training data.
Why Does It Generalize Better?
The prevailing explanation for the second descent relies on the concept of an implicit bias inherent in optimization algorithms like Stochastic Gradient Descent (SGD). When navigating an overparameterized landscape, SGD does not pick just any solution; it naturally selects the "smoothest" or "minimum-norm" solution.
By spreading the function's complexity across an extreme abundance of parameters, the model eliminates jagged, high-frequency oscillations between data points. Effectively, the extra parameters act as an implicit regularizer, smoothing out the interpolation function and allowing the network to robustly capture the true underlying data distribution.
Conclusion
The discovery of double descent has revolutionized our understanding of machine learning architectures. It proves that scaling models to extreme sizes isn't just about raw computational power; it fundamentally shifts the mathematical dynamics of how neural networks generalize. Embracing overparameterization allows AI systems to bypass the treacherous interpolation peak, unlocking unprecedented levels of performance and stability.